VITS [ICML 2021]
in Seminar on Text-to-Speech
- Jaehyeon Kim, Jungil Kong, and Juhee Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech.”, PMLR, 2021
Goal
Presenting a parallel end-to-end TTS method that generates more natural sounding audio than current two-stage models
Motivations
- 기존의 TTS 시스템은 2-stage로 나뉘어서 independent하게 학습됨
- The first stage : the processed text ⇒ the intermediate speech representations(e.g., Mel-spectrograms)
- Autoregressive model(e.g., Tacotron 2), Parallel TTS(i.e. FastSpeech), Likelihood-based methods (i.e. Glow-TTS)
- The second stage : Conditioned on the intermediate representations ⇒ raw waveforms
- Gan-based feed-forward network (e.g., MelGAN, HiFi-GAN)
- The first stage : the processed text ⇒ the intermediate speech representations(e.g., Mel-spectrograms)
- 2-stage pipeline은 sequential training과 고품질의 음성을 위해서 fine-tuning이 필요하다는 단점이 있음
- second stage의 모델은 first stage의 모델이 생성한 샘플로 보통 학습이 되기 때문에, 이 predefined intermediate features에 대한 dependency가 performance을 향상시키는데 방해 요소가 됨
- 그래서 FastSpeech 2s나 EATS처럼 end-to-end로 text나 phoneme sequence로부터 바로 entire waveforms를 생성하는 모델이 제안됐지만, 생성된 음성의 품질이 2-stage TTS system보다 좋지 않았음
본 논문에서는, 현재 two-stage TTS system보다 더 자연스러운 음성을 생성할 수 있는 parallel end-to-end TTS 모델인 VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)를 제안함
아래 3가지의 subsection으로 제안된 모델을 설명하고 있음
- A conditional VAE formulation
- Alignment estimation derived from variational inference
- Adversarial training for improving synthesis quality
- VAE를 사용해서, latent variables를 통해 TTS 시스템의 2가지 모듈을 연결해서 효율적으로 학습함
- Conditional prior distribution에 normalizing flow를 적용하고, waveform domain에서 adversarial training을 적용해서, 고품질의 음성을 생성할 수 있도록 표현력을 향상시킴
- Text와 Speech사이의 one-to-many problem(text ⇒ multiple ways with different variation e.g., pitch and duration)을 해결하기 위해, stochastic duration predictor를 제안하여 다양한 rhythms의 음성을 생성
- Glow-TTS with HiFi-GAN(the best publicly available TTS system)보다 더 자연스러운 음성을 생성하고 높은 sampling efficiency를 보여줌
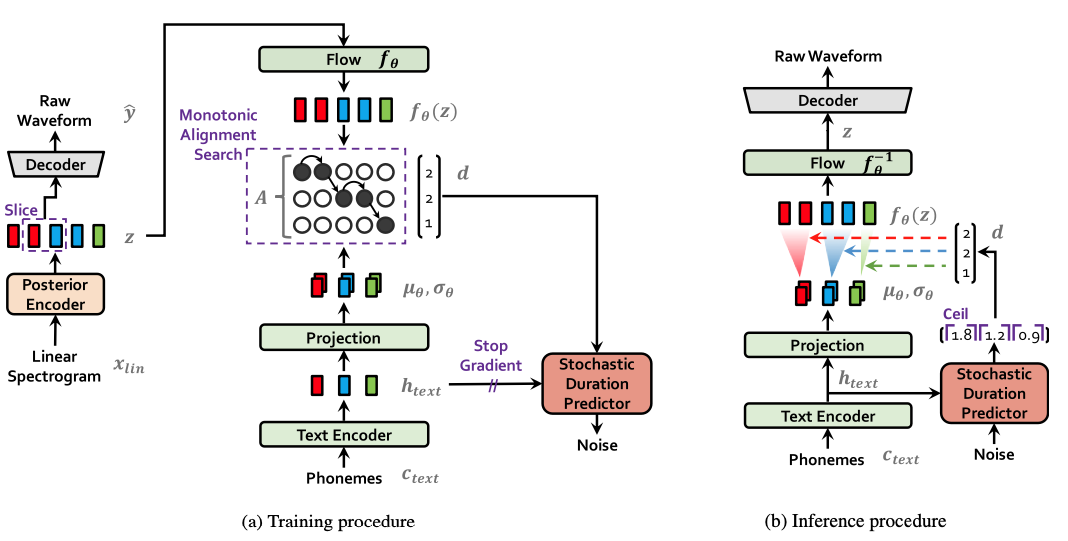
Figure 1. System diagram depicting (a) training procedure and (b) inference procedure.
Variational Inference
VITS는 conditional VAE로 표현 가능함
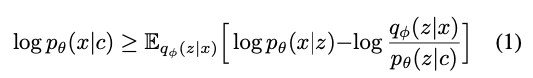
The variational lower bound, also called the evidence lower bound (ELBO), of the intractable marginal log-likelihood of data
- 목적 함수로 $\log p_{\theta}(x \mid c)$의 ELBO를 최대화
- $\log p_{\theta}(x \mid c)$: the intractable marginal log-likelihood of data
- $p_{\theta}(z \mid c)$: a prior distribution of the latent variable $z$ given condition c
- $p_{\theta}(x \mid z)$: the likelihood function of a data point $x$
- $q_{\phi}(z \mid x)$: an approximate posterior distribution
- Reconstruction loss인 $\log p_{\theta}(x \mid z)$와 KL-divergence term인 $\log q_{\phi}(z \mid x)- \log p_{\theta}(z \mid c)$의 합인 negative ELBO가 training loss로 정해짐 (where $z \thicksim q_{\phi}(z \mid x)$)
- Reconstruction loss
- target data point로는 waveform이 아닌 mel-spectrogram $x_{mel}$을 사용함
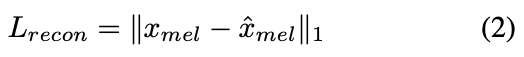
The L1 loss between the predicted and target mel-spectrogram used as the reconstruction loss
- Upsampling through decoder : the latent variables $z$ ⇒ waveform domain $\hat y$
- Transforming by STFT : waveform domain $\hat y$ ⇒ mel-spectrogram domain $\hat x_{mel}$
- mel-spectrogram domain에서 reconstruction loss를 정의한 이유는 perceptual quality를 좋게 만들기 위해서 mel-scale을 사용함
- mel을 추출하는 것은 training때만 활용되고 inference때는 활용되지 않음
- 실제로는 whole latent variable $z$를 upsampling하는 것이 아니라, decoder의 input으로 partial sequences를 사용함
- KL-divergence loss
- Posterior encoder에 좀 더 고해상도의 정보를 제공하기 위해서, mel이 아닌 target speech의 linear-scale spectrogram인 $x_{lin}$을 input으로 사용함
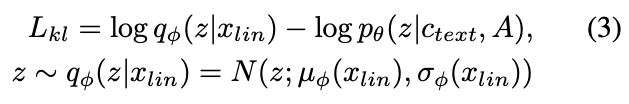
The KL divergence loss
- Prior encoder $c$의 input condition: phonemes $c_{text}$, Alignment $A$ between phonemes and latent variables
- Prior encoder와 posterior encoder를 parameterize하는데 factorized normal distribution이 사용됨
- 현실적인 음성 샘플을 만들기 위해서는, prior distribution의 표현력을 증가시키는 것이 중요하다고 언급함
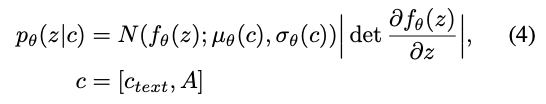
Applying a normalizing flow on top of the factorized normal prior distribution
- 그래서 top of the factorized normal prior distribution에 normalizing flow $f_\theta$를 적용함
Alignment Estimation
- Glow-TTS에서 사용했던 Monotonic Alignment Search (MAS)를 활용함
- input text와 target speech 사이의 monotonic and non-skipping alignment $A$를 추정
- Glow-TTS에서는, normalizing flow $f$에 의해 parametrize된 data의 likelihood를 최대화하는 alignment $A$를 찾는 것이 목적
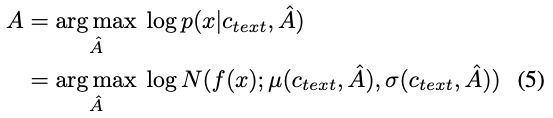
An alignment that maximizes the likelihood of data parameterized by a normalizing flow $f$
Glow-TTS와 다르게, 정확한 log-likelihood가 아닌 objective인 ELBO를 최대화해야하기 때문에, ELBO를 최대화하는 alignment를 찾는 것으로 MAS 알고리즘을 재정의해야함
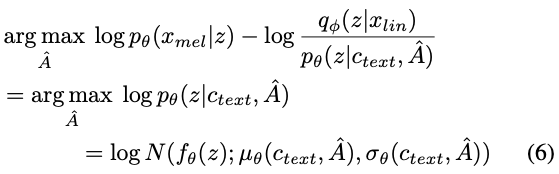
Redefining MAS to find an alignment that maximizes the ELBO
- 그런데 원래의 식인 (5)와 (6)을 비교해보면 크게 차이가 없기때문에 수정없이 original MAS를 사용가능
- Duration prediction from text
- input token인 $d_i$의 duration을 MAS로 추정한 alignment인 $\Sigma_{j}A_{i,j}$으로 계산함
- Glow-TTS에서는, deterministic duration predictor를 학습시켜서 inference때 사용했지만, 본 논문에서는 주어진 phoneme들의 duration distribution을 모델링하는 stochastic duration predictor를 학습시켜서 inference때 사용하는 것을 제안함
- Stochastic duration predictor는 flow기반의 생성 모델이고 maximum likelihood estimation을 통해 학습함
- 각 input phoneme의 duration이 discrete integer이고 scalar이기 때문에, maximum likelihood estimation을 바로 적용하기에는 어려움
- continuous normalizing flow에 적용하기 위해서 dequantizing이 필요하고 invertible하지 않기 때문임
- 그래서 variational dequantization과 variational data augmentation을 적용함
- 2개의 random variable인 $u$와 $v$을 사용 (duration sequence $d$와 같은 time resolution과 dimension임)
- $u$: $[0,1)$ ⇒ $d-u$ $> 0$
- $d-u$는 positive real number의 sequence가 되고, 여기에 $v$를 concat해서 higher dimensional latent representation을 만듬
- approximate posterior distribution인 $q_{\phi}(u,v \mid d, c_{text})$를 통해서, $u$와 $v$를 샘플링함
- stochastic duration predictor의 목적함수는 phoneme duration log-likelihood의 variational lower bound가 됨
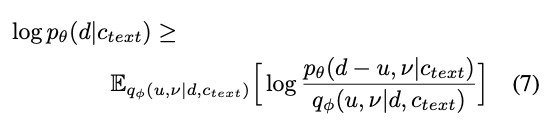
The resulting objective: a variational lower bound of the log-likelihood of the phoneme duration
- Training loss인 $L_{dur}$은 negative variational lower bound가 됨
- Stop gradient operator를 사용해서, duration predictor의 학습이 다른 모듈에 영향을 주지 않도록 함
Adversarial Training
- 전체 학습 과정에서 adversarial training을 적용함
- Discriminator $D$를 decoder $G$가 생성한 waveform과 ground truth waveform $y$를 분류하도록 추가함
- 총 2개의 loss를 speech synthesis를 위해 사용
- The least-squares loss function for adversarial training ($L_{adv}$)
- The additional feature matching loss for training the generator ($L_{fm}$)
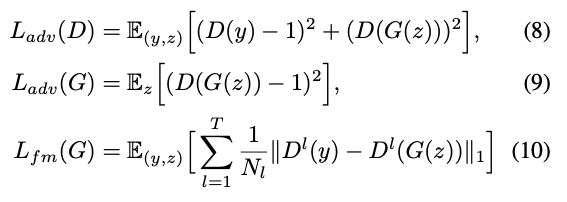
The least-squares loss function for adversarial training, and the additional feature-matching loss for training the generator
- $T$: the total number of layers in the discriminator
- $D^l$: outputs the feature map of the $l$-th layer of the discriminator with $N_l$ number of features
Final Loss
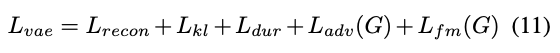
Final loss
- 본 논문이 제안하고 있는 VITS, conditional VAE를 학습하기 위한 total loss는 위와 같음
Model Architecture
Posterior encoder, Prior encoder, Decoder, Discriminator, Stochastic duration predictor로 구성됨
여기서 Discriminator와 Posterior encoder는 Training때만 사용됨
Posterior Encoder
- WaveGlow에서 사용한 non-causal WaveNet residual block을 사용함
- WaveNet residual block은 gated activation unit, skip connection과 함께 dilated convolutions layer로 이루어짐
- 마지막 layer에 linear projection layer를 둬서 normal posterior distribution의 mean과 variance를 생성함
- Multi-speaker setting에서, residual block에 Global conditioning으로 speaker embedding을 더해줌
Prior Encoder
- Text encoder와 Normalizing flow $f_\theta$로 구성됨
- Text encoder로 Transformer encoder를 활용했고, relative positional representation을 사용함
- Text encoder를 통해, input phonemes $c_{text}$로부터 hidden representation인 $h_{text}$를 얻음
- Text encoder뒤에 linear projection layer를 붙여서 prior distribution을 만드는데 사용할 mean과 variance를 생성함
- Normalizing flow는 affine coupling layer의 stack으로 구성되고, 각 affine coupling layer는 WaveNet residual blcok의 stack으로
- Multi-speaker setting에서, normalizing flow의 residual block에 global conditioning으로 speaker embedding을 더해줌
Decoder
- HiFi-GAN V1 generator를 활용함
- Transposed convolutions의 stack으로 구성되고, 각 Transposed convolution뒤에 multi-receptive field fusion module (MRF)를 붙임
- MRF의 output은 각각 다른 receptive field size를 가지는 residual block의 output의 합
- Multi-speaker setting에서, speaker embedding vector로 변환하는 linear layer를 추가해서 speaker embedding을 input latent variable $z$에 더해줌
Discriminator
- HiFi-GAN에서 제안된 multi-period discriminator의 구조를 활용함
- 각 window-based sub-discriminators는 input waveform의 다른 periodic pattern을 잡는데 사용됨
Stochastic Duration Predictor
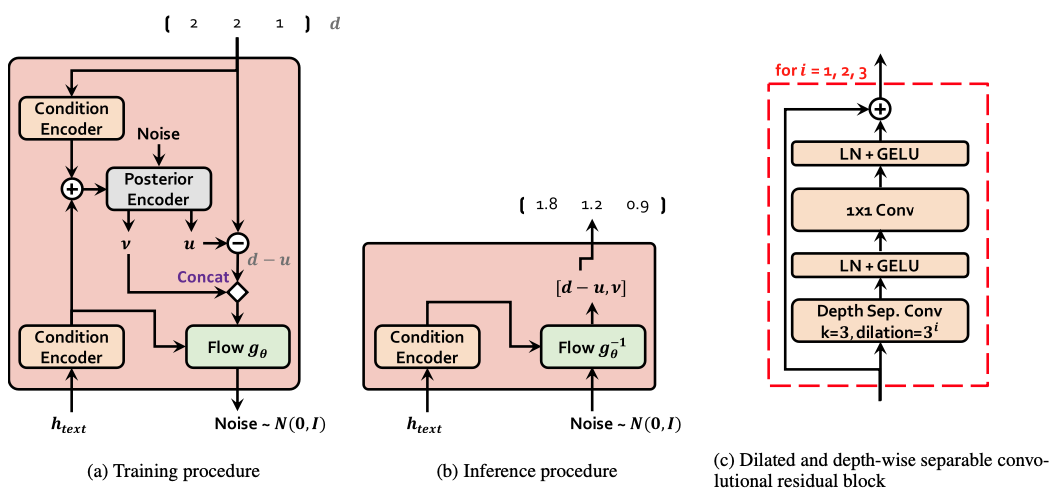
Figure 5. Block diagram depicting (a) training procedure and (b) inference procedure of the stochastic duration predictor. The main building block of the stochastic duration predictor is (c) the dilated and depth-wise separable convolutional residual block.
- $c_{text}$의 hidden representation인 $h_{text}$로부터 phoneme duration의 distribution을 추정함
- Duration predictor에서 normalizing flow 모듈과 posterior encoder는 flow-based neural network이고 비슷한 구조를 가짐
- Posterior encoder에서는 Gaussian noise sequence를 $v$와 $u$로 변환해서, approximate posterior distribution인 $q_{\phi}(u,v \mid d, c_{text})$을 표현함
- Normalizing flow 모듈에서는 $d-u$와 $v$를 Gaussian noise sequence로 변환해서, the augmented and dequantized data의 log-likelihood인 $\log p_\theta(d-u, v \mid c_{text})$를 표현함
- Coupling layer에 Neural spline flow를 적용함 Neural spline flow는 흔히 affine coupling layer에 사용되는 파라미터 수와 비슷한 파라미터를 사용하지만 transformation expressiveness가 더 좋음
- 모든 input condition은 condition encoder를 통해서 process
Dilated and depth-separable convolution layer (DDSConv)로 이루어진 residual block을 사용해서 large receptive field size를 유지하면서 parameter efficiency를 향상시킴
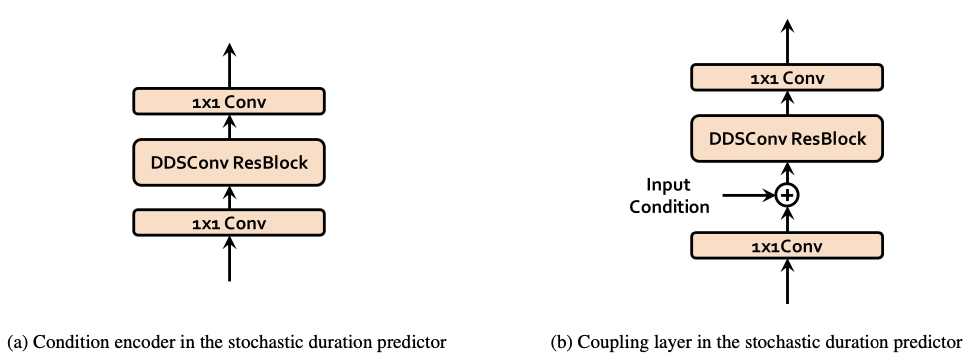
Figure 6. The architecture of (a) condition encoder and (b) coupling layer used in the stochastic duration predictor.
- Multi-speaker setting에서, speaker embedding vector로 변환하는 linear layer를 추가해서 speaker embedding을 input인 hidden representation, $h_{text}$에 더해줌
Experiments
Datasets
Single speaker setting ⇒ LJ Speech dataset 활용
- 13100개의 short audio clip, single speaker, 약 24 hours
- 16-bit PCM, 22 kHz sample rate
- Training set (12500 samples) / Validation set (100 samples) / Test set (500 samples)
Multi speaker setting ⇒ VCTK dataset 활용
- 44000개의 short audio clip, 109명의 native English speaker, 약 44시간
- 16-bit PCM, 44 kHZ sample rate
- 22 kHz로 downsampling을 해서 사용
- Training set (43470 samples) / Validation set (100 samples) / Test set (500 samples)
Preprocessing
- Posterior encoder의 input으로 사용할 linear spectrogram을 STFT를 통해 얻음
- FFT size : 1024
- window size : 1024
- hop size : 256
- Prior encoder의 input으로 IPA phoneme sequences를 사용함
Speech synthesis quality
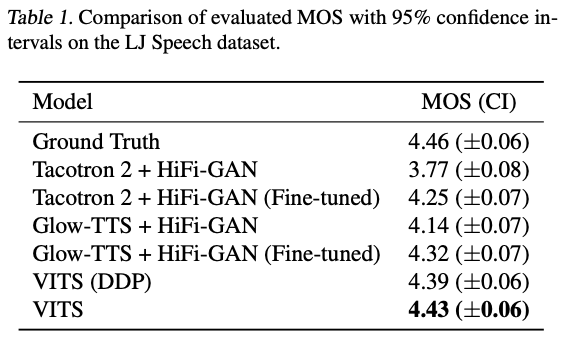
Table 1
- Stochastic duration predictor가 더 현실적인 Phoneme duration을 만듬
- Two-stage 모델보다 VITS가 더 자연스러운 음성 샘플을 생성함
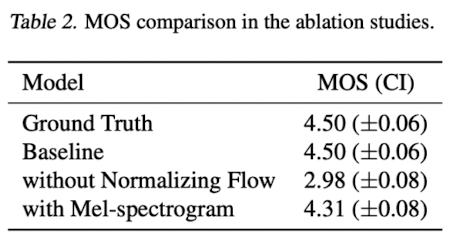
Table 2
- Normalizing Flow를 적용하지 않은 경우를 보아, Prior distribution의 flexibility가 synthesis quality에 중요하다는 것을 알 수 있음
- Posterior input으로 linear-scale의 spectrogram이 아닌 mel을 사용한 경우를 보아, high-resolution information인 linear-scale의 spectrogram을 사용한 것이 synthesis quality를 더 좋게 만드는데 효과적임을 알 수 있음
Generalization to Multi-Speaker Text-to-Speech
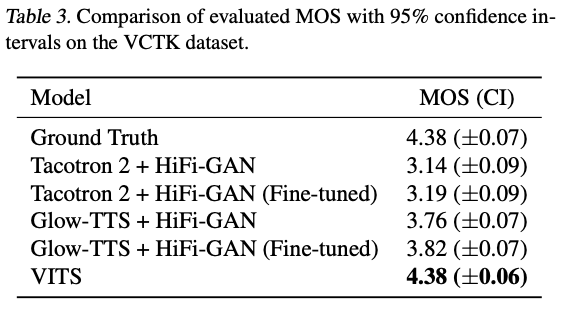
Table 3
- VCTK dataset으로 학습한 multi-speaker setting에서도 VITS가 가장 자연스러운 샘플을 생성함
Speech Variation
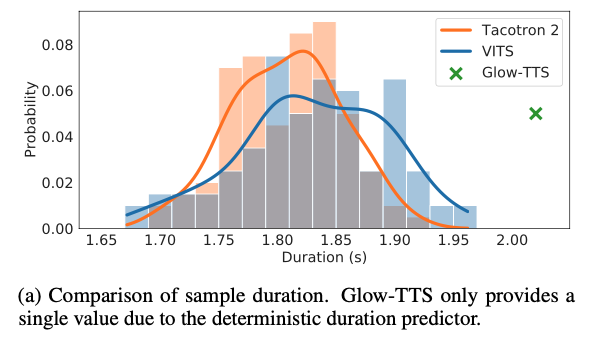
Figure 2.(a) Sample duration on LJ Speech dataset
- Stochastic duration predictor가 얼마나 다양한 길이의 speech를 생성하는지 확인한 결과임
- 각 모델이 생성한 100개의 utterance의 길이 분포
- Glow-TTS는 deterministic duration predictor를 사용하기 때문에, 고정된 길이의 utterance만을 생성
- VITS는 Tacotron 2와 비슷한 길이의 distribution을 보여주는 것을 확인할 수 있음
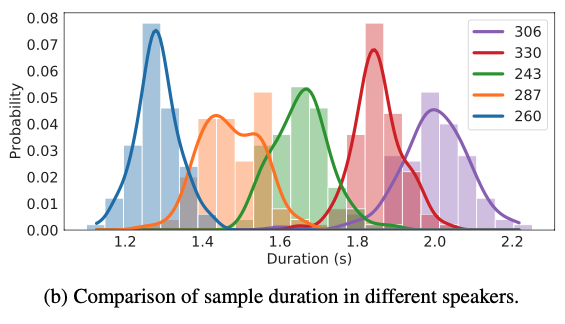
Figure 2.(b) Sample duration on VCTK datset
- 생성된 샘플이 얼마나 다른 speech characteristics를 가지는지 확인한 결과임
- 각 5명의 speaker identity로 VITS가 생성한 100개의 utterance 길이 분포
- VITS가 multi-speaker setting에서 speaker-dependent phoneme duration을 잘 학습하는 것을 확인할 수 있음
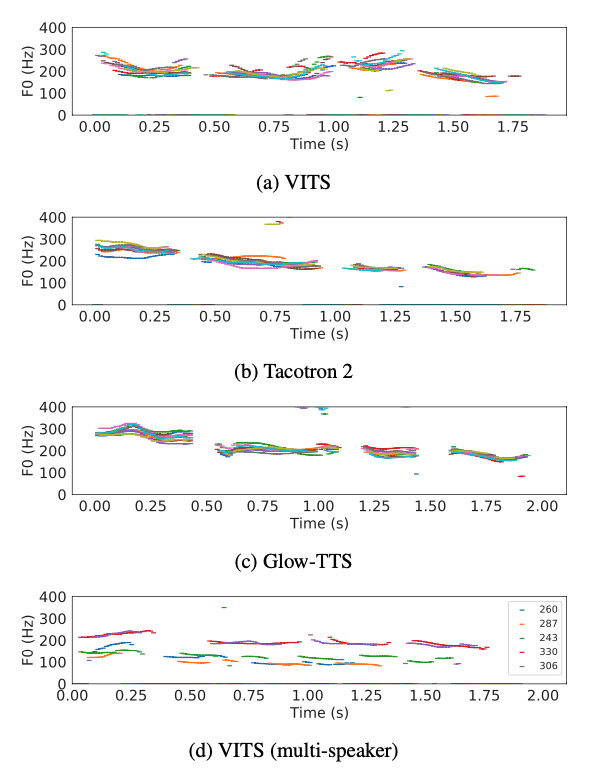
Figure 3. Pitch tracks for the utterance “How much variation is there?”.
- 10개의 utterance에서 YIN 알고리즘을 통해 추출한 $\text F0$ contours를 보여줌
- VITS가 다양한 pitch와 rhythm의 speech를 생성하는 것을 확인할 수 있음
- (d)는 각각 다른 speaker identity를 가지고 생성한 5개의 utterance를 보여주는데, 각 speaker identity에 따라 다른 length와 pitch를 가지는 것을 확인할 수 있음
- VITS는 prior distribution의 standard deviation을 증가시켜서 pitch의 다양성을 증가시킬 수 있지만, synthesis quality는 낮아질 수 있음
Synthesis Speed

Table 4
- VITS는 predefined intermediate representations을 생성하는 first stage의 모듈이 필요 없기 때문에, synthesis speed와 sampling efficiency가 훨씬 좋은 것을 확인할 수 있음
Voice Conversion
- $z \thicksim q_{\phi}(z \mid x_{lin},s)$, $e=f_\theta(z \mid s)$
- $s:$ speaker identity, $x_{lin}:$ a linear spectrogram from an utterance of the speaker $s$
- $\hat y=G(f^-1_\theta(e \mid \hat s) \mid \hat s)$
- $\hat s:$ target speaker identity
- 위의 식처럼, target speaker $\hat s$의 목소리로 바꿔서 음성을 생성할 수 있음
Glow-TTS와 다른 점은, VITS는 mel-spectrogram이 아닌 raw waveform을 제공함
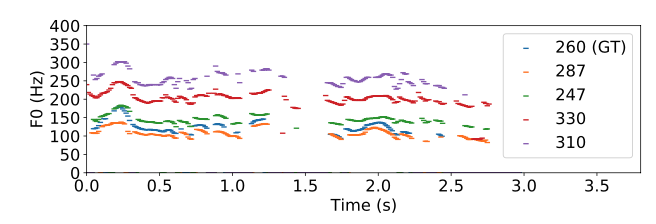
Figure 7. Pitch tracks of a ground truth sample and the corresponding voice conversion samples with different speaker identities.
- 다른 speaker identity를 가지고 Voice conversion task를 수행할 때, 생성된 음성 샘플들이 비슷한 trend를 가지면서 다른 pitch level을 가지는 것을 확인할 수 있음
Conclusion
- End-to-End 방식으로 text sequence로부터 Waveform을 학습하고 생성할 수 있는 parallel TTS인 VITS를 제안함
- Speech의 다양한 rhythms을 표현하기 위해 stochastic duration predictor를 제안함
- VITS는 기존의 2-stage TTS 시스템보다 자연스럽고 사람과 비슷한 음성을 생성함
References
Kim, Jaehyeon, Jungil Kong, and Juhee Son. “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech.”, PMLR, 2021.
Kong, Jungil, Jaehyeon Kim, and Jaekyoung Bae. “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis.”, NeurIPS, 2020.
Kim, Jaehyeon, et al. “Glow-tts: A generative flow for text-to-speech via monotonic alignment search.”, NeurIPS, 2020.
Rezende, Danilo, and Shakir Mohamed. “Variational inference with normalizing flows.”, PMLR, 2015.
Ren, Yi, et al. “Fastspeech 2: Fast and high-quality end-to-end text to speech.”, ICLR, 2021.
Shen, Jonathan, et al. “Natural tts synthesis by conditioning wavenet on mel spectrogram predictions.”, ICASSP, 2018.
Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.”, ICLR, 2013.
Goodfellow, Ian, et al. “Generative adversarial nets.”, NeurIPS, 2014.