Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search
in Seminar on Text-to-Speech
Goal
Proposing Glow-TTS, a flow-based generative model for parallel TTS that does not require any external aligner
Motivation
Autoregressive TTS models (e. g. Tacotron 2, Transformer TTS)
- 모델이 생성하는 Output의 길이에 따라 inference time이 linearly 증가함
대부분 Autoregressive 모델은 Robustness가 부족함
반복되는 단어가 input으로 들어오면, 꽤 심각한 attention error가 생긴다
Parallel TTS models (e. g. FastSpeech)
Parallel TTS 모델을 학습하기 위해서는 well-aligned attention map(text와 speech)이 필요함
FastSpeech의 경우, pre-trained autoregressive TTS model의 attention map을 활용한다
이 경우, 모델의 성능이 external aligners에 의존한다는 단점이 있다
Combining the properties of flows and dynamic programming
본 논문에서는, parallel TTS에서 필요했던 external aligner를 제거하고 Parallel TTS model의 학습 과정을 간단하게 만들었음
즉, Parallel TTS를 위해서, 내부적으로 alignment를 직접 학습하고 flow기반 generative model인 Glow-TTS를 제안하고 있음
Glow-TTS는 speech latent representation과 text사이의 가장 가능성이 높은 monotonic alignment를 search함
이 alignment를 가지고 speech의 log-likelihood를 최대화하도록 학습을 진행하는 것임
Hard monotonic alignment를 enforcing하는 것을 통해 robust TTS를 만들 수 있고, flow를 활용함으로써 fast, diverse and controllable speech synthesis가 가능하다
Training and Inference Procedures
Glow-TTS
Generating : A mel-spectrogram
Conditioned on : A monotonic and non-skipping alignment between text and speech representations
본 논문에서 언급하기를, 사람이 text를 순서대로 읽는 방식에 영감을 받아 단어를 skipping하는 것 없이 monotonic alignment를 condition으로 mel을 생성한다고 함
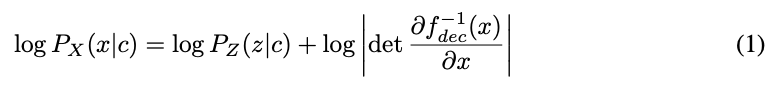
Equation 1. Calculating the exact log-likelihood of the data by using the change of variables
- $P_{X}:$ The log-likelihood of the data
- $P_{Z}:$ The prior distribution
- $P_{X}(x\mid c):$ The conditional distribution of mel-spectrograms
- $P_{Z}(z\mid c):$ The conditional prior distribution
- $f_{dec}:$ The flow-based decoder
- $x:$ The input mel spectrogram
- $c:$ The text sequence
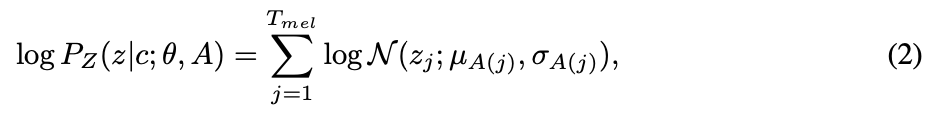
Equation 2. Calculating the prior distribution with parameters $\theta$ and an alignment function $A$
$P_{Z}:$ The prior distribution that is the isotropic multivariate Gaussian distribution
음성 데이터의 각 잠재 변수 $z_{j}$가 text encoder로부터 생성된 statistic, 즉 평균 $u_i$와 표준 편차 $\sigma_{i}$에 기반한 정규 분포를 따른다라는 기본 아이디어임
- $u, \sigma:$ The statistics of the prior distribution obtained by the text encoder $f_{enc}$
- $f_{enc}:$ The text encoder mapping the text condition $c(c_{1:T_{text}})$ to the statistics $u,\sigma$ ($u=u_{1:T_{text}},\sigma = \sigma_{1:T_{text}}$ )
- $T_{text}$: The length of the text input
- $T_{mel}:$ The length of the input mel-spectrogram
$A:$ The alignment function mapping from the index of the latent representation of speech to that of statistics from $f_{enc}$
Text input을 반복하거나 생략하지 않도록, monotonic과 surjective alignment function $A$를 가정해서 사용하고 있음
- 단조성(Monotonicity): 함수가 한 방향으로만 움직이고, 뒤로 가거나 반복되지 않는다는 것을 의미함즉, Glow-TTS가 텍스트를 건너뛰거나 반복하지 않기 위해 사용함
- 전사성(Surjectivity): 함수가 출력 공간의 모든 가능한 값들을 적어도 한 번씩은 다룬다는 것을 의미함 즉, 모든 text가 mel에 mapping될 수 있음을 보장함
$A(j)=i$, if $z_j \sim N(z_{j};u_i,\sigma_{i})$
여기서 $j$가 The index of the latent representation of speech, $i$가 index of statistic from $f_{enc}$
잠재 변수 $z_{j}$가 text encoder에서 생성된 $u_{i}$와 $σ_i$를 기반으로 하는 정규 분포 $N(z_j;u_i,\sigma_i)$를 따른다는 것을 의미함
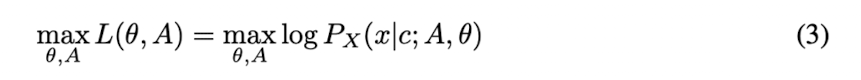
Equation 3. The log-likelihood of the data
이제 data의 log-likelihood를 최대화하는 parameter $\theta$와 alignment $A$를 찾아야 하는데,
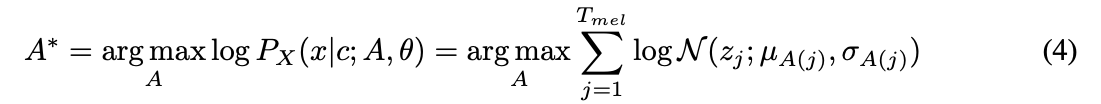
Equation 4. The most probable monotonic alignment $A^*$
- 현재 parameter $\theta$에 관해서, 가장 가능성이 높은 monotonic alignment를 먼저 찾기
- $\log p_{X}(x \mid c;\theta,A^*)$를 최대화하도록 parameter $\theta$를 업데이트
Global solution을 찾기 힘들기 때문에, 위와 같은 순서로 나눠서 학습을 진행하고 parameter와 alignment의 search space를 줄이고자 함
실제로 학습때 위 과정을 반복하는데, 각 training step마다 $A^*$를 먼저 찾고 gradient descent를 통해서 $\theta$를 업데이트하는 것임
이러한 방식이 Global solution을 보장하지는 못하지만, global solution의 good lower bound를 제공한다고 언급하고 있음
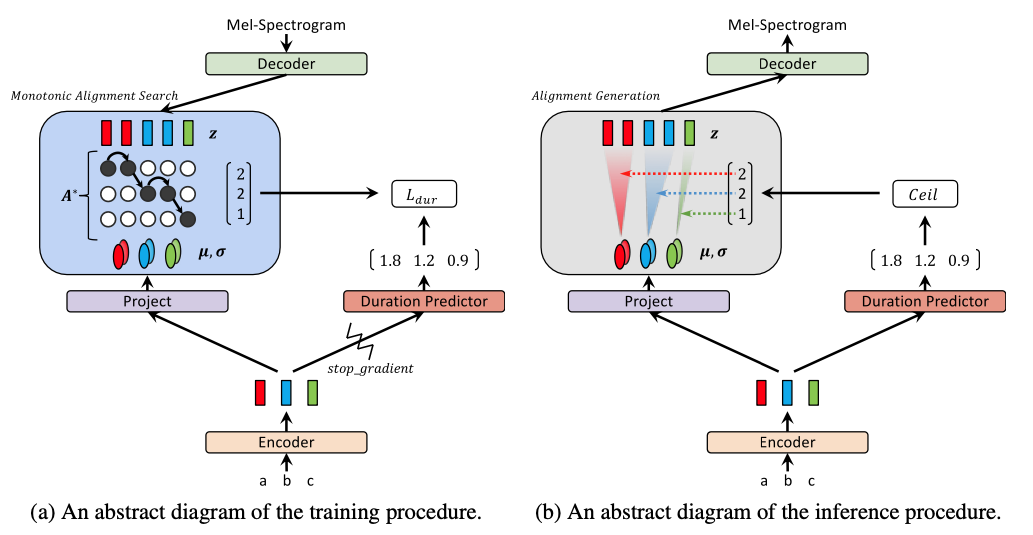
Figure 1. Training and inference procedures of Glow-TTS
Inference를 할 때, $A^*$를 추정하기 위해 duration predictor인 $f_{dur}$도 같이 학습을 함
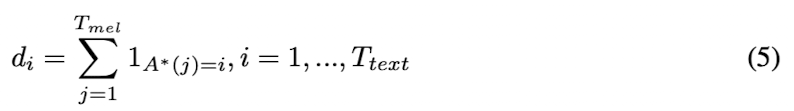
Equation 5. The duration label calculated from the alignment $A^*$
$A^*$로부터 duration label을 위와 같이 구해서 text와 matching하도록 학습시키고, FastSpeech의 구조처럼 text encoder 위에 추가되어 Mean Squared Error (MSE) loss로 학습을 함
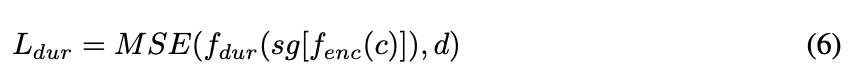
Equation 6. The loss for duration predictor
duration predictor의 loss식에서 duration predictor의 input에 stop gradient operator인 $sg[⋅]$를 사용하고 있음
$sg[⋅]:$ backward pass에서 input의 gradient를 제거해서 maximum likelihood objective에 영향을 주는 것을 방지하는 역할
즉, Inference를 할 때,
The text encoder : Prior distribution의 $u, \sigma$를 predict
The duration predictor : Alignment를 predict
The flow-based decoder : mel-spectrogram을 synthesis, in parallel by transforming the latent variable(sampled from the prior distribution)
Monotonic Alignment Search
Equation 4. The most probable monotonic alignment $A^*$
앞서 언급한 latent variable($z$)과 the statistics of the prior distribution($u, \sigma$)간의 the most probable monotonic alignment $A^*$를 찾기 위해,
본 논문에서는 Monotonic Alignment Search (MAS)라는 search 알고리즘을 제안하고 있음

Algorithm 1. MAS
시간 복잡도 : $O(T_{text} \times T_{mel})$
partial alignment의 solution을 recursive하게 구해서 전체 alignment를 찾는 알고리즘임
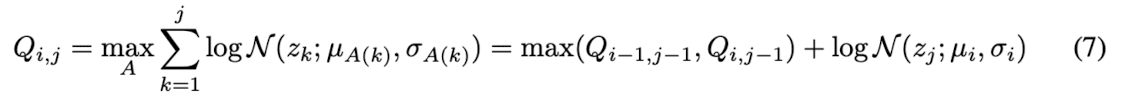
Equation 7. The maximum log-likelihood where the statistics of the prior distribution and the latent variable
$Q_{i,j}:$ the maximum log-likelihood (text의 i번째 elements와 mel의 j번째 latent variable사이의 정렬 비용 또는 유사도를 나타냄)
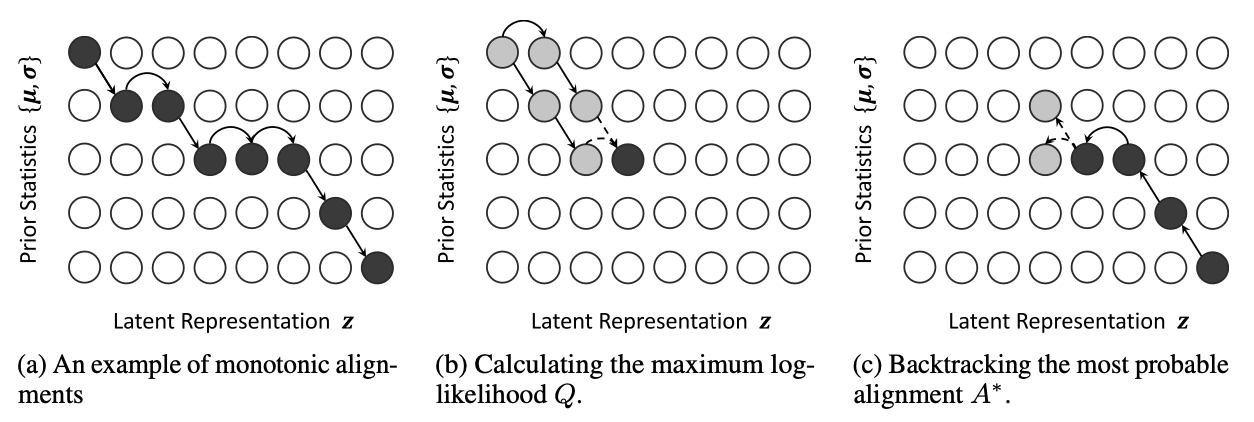
Figure 2. Illustrations of the monotonic alignment search.
$Q_{i,j}$를 $Q_{i-1,j-1}$과 $Q_{i,j-1}$중에서 큰 값으로 구하게 됨
이 방식을 반복적으로 진행해서 모든 $Q$의 값을 구하고 $Q_{T_{text},T_{mel}}$까지 계산함
마지막으로 BackTracking을 통해서 전체의 most probable alignment $A^{}$ 를 구하게 됨, $A^{}(T_{mel})=T_{text}$
$A^{*}$ 가 Dynamic Programming (DP) 방식으로 효율적으로 계산이 가능하다는 것을 보여주고 있음
parallelization하기 어려운 알고리즘이지만 각 iteration마다 20ms보다 작은 시간이 걸렸고 전체 학습 시간의 2%도 안되기 때문에 효율적인 알고리즘이라고 언급하고 있음 (CPU 사용)
Architecture
The encoder architecture
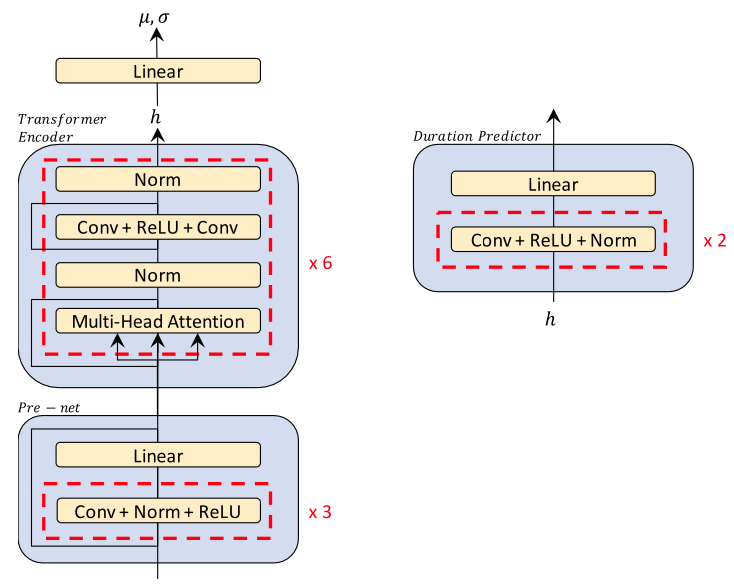
Figure 3. The encoder architecture of Glow-TTS
Transformer TTS기반의 encoder 구조를 활용하고 있는데, 2가지가 수정됨
- self-attention module에서 positional encoding 대신에 relative position representations를 사용
- Encoder pre-net에서 residual connection을 추가
그리고 Prior distribution의 $u$와 $\sigma$를 추정하기 위해서, encoder 뒤에 linear projection layer를 추가
Duration predictor는 FastSpeech의 duration predictor와 구조가 같음 (2 convolution layers with ReLU activation, Layer normalization, Dropout followed by a projection layer)
The decoder architecture
Flow-based decoder를 활용하고 있음
During training : Transforming a mel-spectrogram into the latent representation for maximum likelihood estimation and our internal alignment search
During inference : Transforming the prior distribution into the mel-spectrogram distribution
병렬적으로 forward transformation과 inverse transformation을 수행할 수 있도록, a family of flows로 이루어짐

Figure 4. The decoder architecture of Glow-TTS
전체 Decoder는 a stack of multiple block들로 이루어져 있고, 각 block은 activation normalization layer, invertible 1x1 convolution and coupling layer로 이루어짐
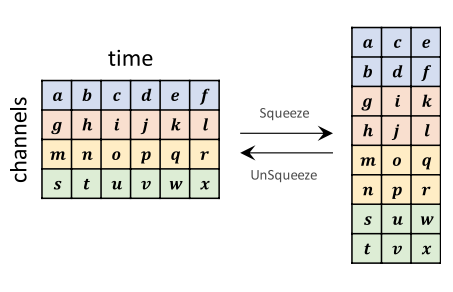
Figure 5. An illustration of Squeeze and UnSqueeze operations
Computational efficiency를 위해서 위의 그림과 같이, flow 연산을 적용하기 전에, 80-channel mel-spectrogram을 time-dimension에서 절반으로 split하고, 하나의 160-channel의 feature map으로 묶음
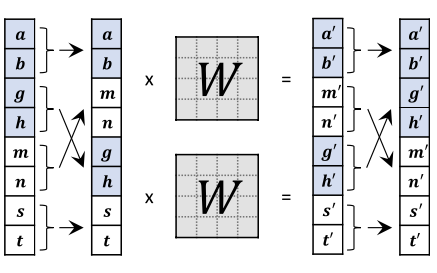
Figure 6. An illustration of our invertible 1x1 convolution
그리고 1x1 convolution을 적용하기 전에, feature map을 channel dimension에서 40 group으로 split하고 각각 따로 1x1 convolution을 수행함
각 그룹에서 channel mixing을 하기 위해서, 위의 그림과 같이, 한 그룹의 절반과 다른 그룹의 절반을 mix함
Experiments
Baseline 모델로 Tacotron 2와 비교하고 있고 vocoder로는 WaveGlow를 사용함
For the single speaker setting
LJSpeech 데이터 셋 사용
a single female speaker, 13100 short audio clips, a total duration of about 24 hours
For the multi-speaker setting
LibriTTS corpus (train-clean-100 subset) 데이터 셋 사용
247 speakers, a total duration of about 54 hours
Speaker embedding을 추가했고 hidden dimension 크기를 증가시킴
Speaker embedding은 global condition으로 decoder의 모든 affine coupling layer에 적용됨
Preprocessing
- Sampling rate: 22,050Hz
- Filter length: 1024
- Hop length: 256
- Window length: 1024
For the Robustness test
227 utterances extracted from the first two chapters of the book Harry Potter and the Philosopher’s Stone
Out-of-distribution text data, 데이터 중 제일 긴 길이가 800이 넘음
Audio Quality

Table 1: The Mean Opinion Score (MOS) of single speaker TTS models with 95% confidence intervals
Prior distribution의 standard deviation(i. e., temperature $T$)를 바꾸면서 실험했을때,
Glow-TTS는 $T=0.333$일 때, 가장 좋은 성능을 보여줌
또 Tacotron2보다 모든 $T$에서 GT에 가까운 성능을 보여주고 있다

Table 2: The Comparative Mean Opinion Score (CMOS) of single speaker TTS models
CMOS 결과를 봐도 Glow-TTS의 성능이 더 좋은 것을 알 수 있음
Sampling speed
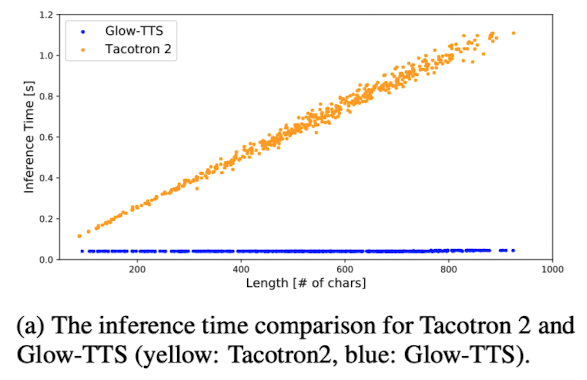
Figure 7. Comparison of inference time
Glow-TTS의 inference time은 input text sequence의 length에 상관없이 거의 상수값을 가지는 것을 확인할 수 있음
그리고 전체 inference time에서 Glow-TTS는 4%, WaveGlows는 96%를 차지한다는 언급에서, 짧은 inference time에서도 Glow-TTS가 mel을 만드는 시간은 꽤 짧다는 것을 알 수 있음
Robustness
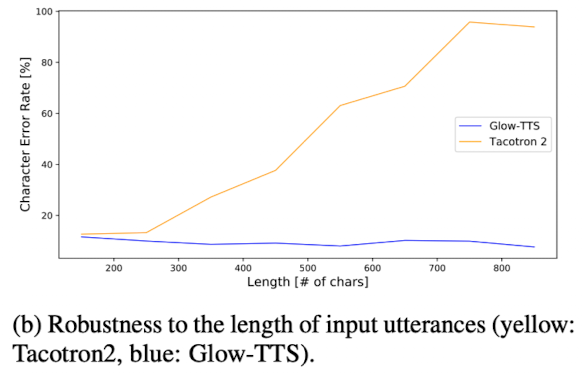
Figure 8. Comparison of length robustness
The book Harry Potter and the Philosopher’s Stone에서 긴 utterance의 sample을 생성하는 실험에서 character error rate (CER)을 측정함
Tacotron 2에서는 input characters 길이가 260을 초과하면 CER이 증가하는 것을 볼 수 있지만,
Glow-TTS에서는 input characters 길이와 무관하게 긴 sequence에서도 robustness를 보여주고 있음

Table 3: Attention error counts for TTS models on the 100 test sentences.
Attention errors를 다른 모델들과 비교해서 분석한 결과인데,
Tacotron 2와 Glow-TTS에서 attention error가 덜 발생하는 것을 확인할 수 있음
Tacotron 2는 location sensitive attention을 사용하기 때문에 attention error가 적은 것을 확인할 수 있고,
비슷하게 Glow-TTS도 attention error가 덜 발생하면서도 긴 sentences에서도 robustness를 보여준다는 것을 확인할 수 있음
Diversity and Controllability
Glow-TTS는 flow기반 모델이기 때문에 다양한 sample들을 생성할 수 있음
latent representation인 $z \sim N(u,T)$는

Equation 8. The latent representation $z$
와 같이 표현 가능함
- $u:$ the mean of prior distribution
- $T:$ the standard deviation( i.e., temperature) of prior distribution
- $\epsilon:$ A sample from the standard normal distribution
$\epsilon$와 $T$를 다르게 값을 주면서 다양한 sample들을 만들 수 있음
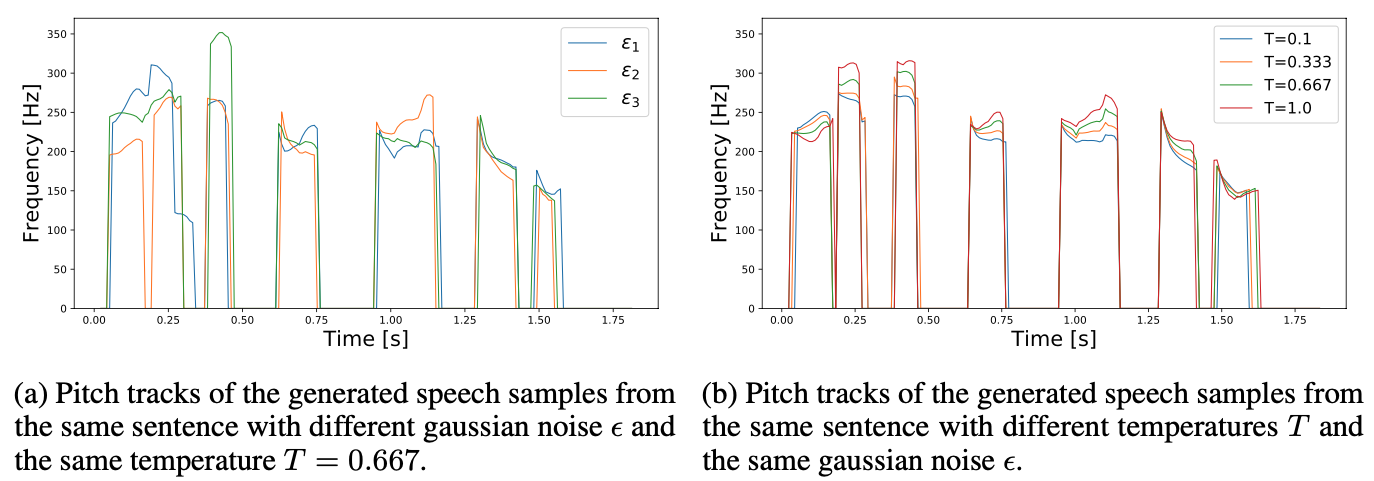
Figure 9: The fundamental frequency (F0) contours of synthesized speech samples from Glow-TTS trained on the LJ dataset
(a)에서 볼 수 있듯이, $\epsilon$을 통해 다양한 stress나 intonation pattern을 만들 수 있음을 확인할 수 있고
(b)에서 볼 수 있듯이, $T$를 통해 비슷한 intonation을 유지하면서 speech의 pitch를 조절할 수 있는 것을 확인할 수 있다
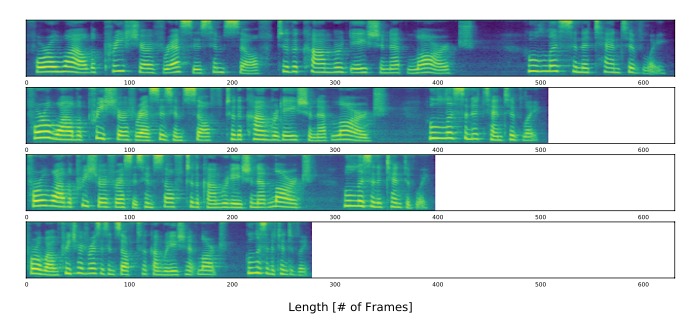
Figure 10: Mel-spectrograms of the generated speech samples with different speaking rates; the values multiplied by the predicted duration are 1.25, 1.0, 0.75, and 0.5.
또한 위의 실험결과를 통해,
positive scalar value를 duration predictor가 예측한 duration에 곱해줌으로써, speaking rate를 조절할 수있는 것을 확인할 수 있다
Multi-Speaker TTS
Audio Quality
Table 4: The Mean Opinion Score (MOS) of a multi-speaker TTS with 95% confidence intervals
multi-speaker TTS에서는 Tacotron 2와 비슷한 성능을 보여줌
Speaker-Dependent Duration
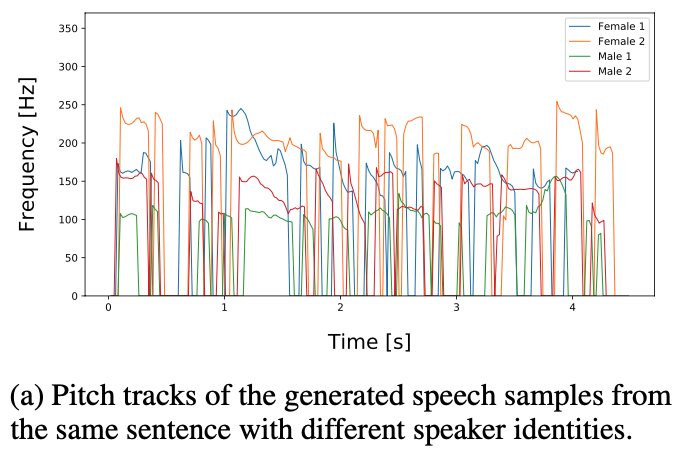
Figure 11-(a): The fundamental frequency (F0) contours of synthesized speech samples from Glow-TTS trained on the LibriTTS dataset
speaker identity만 다르게 줘서 생성한 samples인데,
모델이 speaker의 identity에 따라서 duration을 다르게 예측하는 것을 확인할 수 있음
Voice Conversion
speaker identity 정보를 encoder에 주지 않기 때문에, prior distribution은 speaker identity와 independent함
Glow-TTS는 speaker identity와 latent representation $z$를 disentangle하도록 학습한다는 말임
disentanglement 정도를 확인하기 위해서, GT-mel을 correct speaker identity로 latent representation으로 바꾸고 다시 다른 speaker identity로 mel을 생성함(invert)

Equation 9. The latent representation $z$ through the inverse pass of the flow-based decoder $f_{dec}$ with the source speaker identity $s$

Equation 10. The target mel-spectrogram $\hat{x}$ through the forward pass of the decoder with the target speaker identity $\hat{s}$
위의 식에서 볼 수 있듯이, source speaker $s$의 mel인 $x$를 target mel인 $\hat{x}$로 바꿈

Figure 11-(b): The fundamental frequency ($F0$) contours of synthesized speech samples from Glow-TTS trained on the LibriTTS dataset
similar trend를 유지하면서 다른 pitch level로 바뀐 샘플들을 확인할 수 있음
Conclusion
- Flow-based generative model이자 새로운 parallel TTS model인 Glow-TTS를 제안
- FastSpeech처럼 외부의 aligner를 사용하는 것이 아닌, DP기반의 aligner를 자체적으로 활용
- Baseline인 Tacotron 2보다 inference 속도가 약 15.7배 빠르고 비슷하거나 더 좋은 성능을 보여줌
- Multi-speaker setting에도 적용할 수 있고 speaking rate, pitch control, voice conversion이 가능하고 robustness를 보여줌
Reference
Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search
FastSpeech: Fast, Robust and Controllable Text to Speech
**Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions (Tacotron2)