AdaSpeech
in Seminar on Text-to-Speech
- Mingjian Chen et al., AdaSpeech: Adaptive Text to Speech for Custom Voice, ICLR, 2021
Goal
- 적은 파라미터로 파인튜닝함으로써 커스텀 보이스에 효율적으로 Adaptation 할 수 있는 Adaptive TTS 모델을 제안하였습니다.
Motivation
- Source 스피치 데이터 셋(Training set)과 Target 스피치(Custom voice)은 상당히 다른 Acoustic 조건을 가지고 있습니다. Acoustic 조건들의 Mismatch로 인해 일반화가 어렵고, Adapation 성능도 저하됩니다.
- ex. 프로소디, 스타일, 감정, 악센트, 녹음 환경 .etc
- 기존 연구들은 Source와 Target이 같은 Domain에 있다고 가정하여 Acoustic condition이 다르다는 점을 고려하지 못했습니다.
- Adaptation 성능과 파인튜닝 파라미터 수 사이의 Trade-off 가 존재합니다.
- 기존 연구들은 Trade-off 를 해결하지 못하고, 장단점이 공존하게 모델링했습니다.
Contribution
- Cross-domain dataset을 기반으로, Source 스피치와 Target 스피치의 다양한 Acoustic 조건을 여러 측면(Different granularities)에서 모델링하는 관점을 가지고 Acoustic condition modeling을 제안했습니다.
- Adaptation 효율성을 향상시키기 위해, 적은 Fine-tuning parameters와 High quality를 갖게끔 Conditional layer normalization을 제안했습니다.
Overview
AdaSpeech는 Adaptive TTS 모델 중에서 파인튜닝을 사용하는 모델입니다. 기본 구조로는 FastSpeech2를 사용했고, 새롭게 Acoustic condition modeling과 Conditional layer normalization 부분을 추가해 모델의 Adaptation 성능을 높이고, 파인튜닝의 효율성을 향상시켰습니다.
- Acoustic condition modeling은 크게 스피커 수준, 발화 수준, 음소 수준으로 3가지로 나뉘게 되고, 발화 수준과 음소 수준의 Acoustic 조건은 Acoustic 조건 인코더를 사용해서 Acoustic 조건에 대한 정보를 Phoneme 인코더를 거쳐 만들어진 Hidden phoneme sequence에 더해줍니다.
- Conditional layer normalization은 FastSpeech2 모델 구조에서 적은 파라미터를 가지면서도, 최종 아웃풋에 영향을 많이 미치는 부분이 Layer normalization이라고 생각하였고, Layer normalization 시에 Target 스피커에 관한 정보를 파인튜닝 해주면 효율적인 Adaptation이 가능하다는 아이디어를 갖고 도입했습니다.
모델은 전체적으로 사전학습, 파인튜닝, 인퍼런스 이렇게 총 3가지의 파이프라인으로 나뉘게 됩니다. Source 모델 학습은 60,000~100,000 스텝동안 이루어지고, 파인튜닝은 원하는 스피커의 스피치 20개를 이용해서 2,000 스텝동안 이루어집니다.
Architecture of AdaSpeech
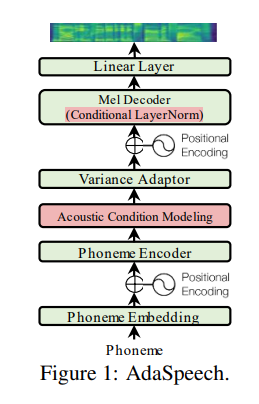
- 기본적인 Backbone 모델은 FastSpeech2 [Y. Ren et al., 2020]을 사용했습니다.
- 추가적으로 Acoustic condition modeling 과 Conditional layer normalization을 사용했습니다.
Acoustic condition modeling
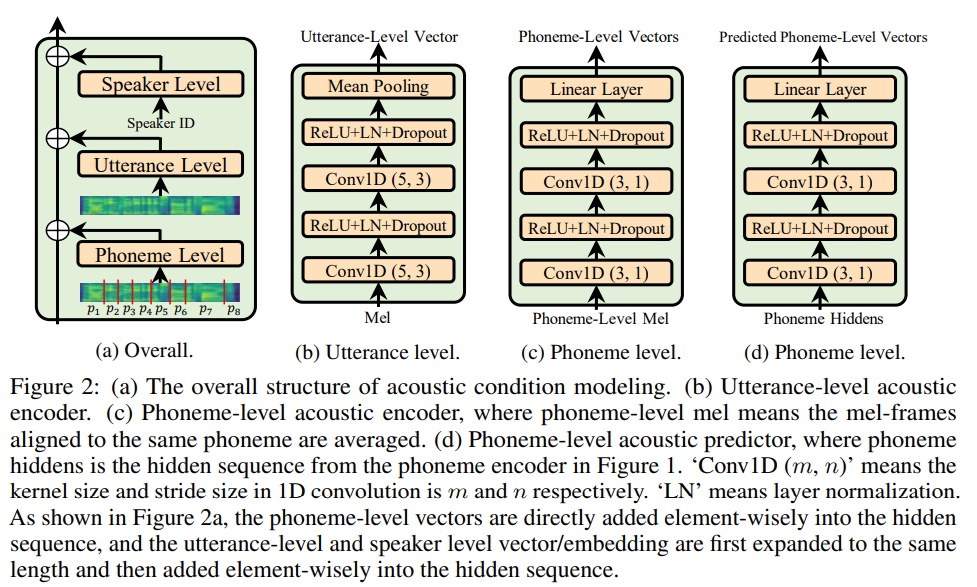
- 배경: 여러개의 커스텀 보이스에 존재하는 수 많은 Acoustic 조건 (프로소디, 스타일, 감정, 악센트, 녹음 환경 등)을 커버하지 못한다면, 모델의 Generalizability (Adaptation 능력)이 떨어지게 됩니다.
- 3가지의 다른 level로 나누어 Acoustic 조건에 대한 정보를 제공했습니다.
- Speaker-level
- 이미 많은 Multi-speaker 시나리오에서 Speaker-level의 Acoustic 조건을 모델링하기 위해서 스피커 ID, 스피커 Embedding 을 사용했습니다.
- 본 모델에서도 스피커 Embedding을 사용함으로써 Speaker의 전체적인 특성을 Capure 할 수 있습니다.
- Utterance-level
- 각 발화자의 발화마다 Acoustic 조건을 Capture 하기 위해 세팅하였습니다.
- 마지막에 Single vector로 만들기 위해서 Mean pooling 레이어를 거치게 됩니다.
- 학습할 때 입력으로 넣어주는 Reference 스피치는 Target 스피치이고,
- 인퍼런스 할 때의 Reference 스피치는 해당 발화자의 스피치 중에서 랜덤하게 고릅니다.
- Phoneme-level
- 각 발화의 Phoneme 마다 특정 Phoneme의 악센트나 피치, 프로소디, 녹음환경 노이즈 등을 Capture 하기 위해 세팅하였습니다.
- Fig 2(a)에서 보이는 것처럼 입력으로 받은 스피치 프레임 시퀀스의 길이를 Phoneme 시퀀스의 길이로 변환하기 위해, 같은 Phoneme에 해당하는 스피치 프레임들을 평균내어 하나의 Phoneme당 하나의 (평균)스피치 프레임을 매칭시켜줍니다. (해당 Alignment는 MFA를 통해 얻었습니다)
- 인퍼런스 동안은, Phoneme-level Acoustic 조건 인코더가 아닌, Phoneme-level Acoustic Predictor를 사용하였습니다. Predictor는 인코더와 동일한 구조를 가졌고, 60,000스텝동안 학습된 인코더의 아웃풋을 Lable로 하여 40,000스텝동안 MSE loss를 최소화하는 방향으로 최적화 됩니다.
- Speaker-level
- 사실 이렇게 인코더를 이용해서 Acoustic한 정보를 넣어주는 연구는 진행되어 왔지만, 저자들은 Different granularities에서 다양한 Acoustic condition을 모델링하고자 한 관점 자체가 Novelity 있다고 말하고 있습니다.
Conditional layer normalization
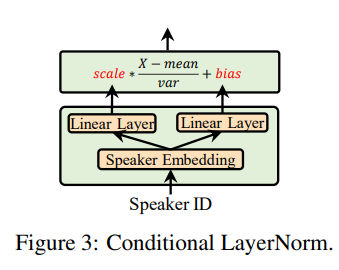
배경: Adaptation 파라미터 수와 높은 퀄리티 사이의 Trade-off를 해결하기 위해서, FastSpeech2 모델 안에서 적은 파라미터를 가지면서도 은닉 벡터와 최종 아웃풋에 영향을 많이 미치는 부분을 찾아보았고, 그 결과 Layer normalization이 적합하다는 결론을 냈습니다. \[LN(x)=\gamma\frac{x-\mu}{\sigma}+\beta\]
- 작은 크기의 Conditional network를 이용해서, 원하는 Speaker의 특성에 대응하는 스케일 벡터와 편향 벡터를 결정할 수 있다면, 새로운 보이스에 Adaptation 할 때, 작은 크기의 Conditional network만 파인튜닝해서 Adaptation 파라미터 수는 줄이고 성능은 높일 수 있습니다.
Method: \[\gamma^s_c =E^s*W^\gamma_c, \ \ \ \beta^s_c=E^s*W_c^\beta\]
- 위 그림처럼 2개의 Linear layer $W_c^\gamma$ 와 $W^\beta_c$ 가 Speaker embedding $E^s$ 를 인풋으로 받아서 스케일 벡터와 편향 벡터를 아웃풋으로 내뱉게 됩니다. $s$는 스피커 ID이고, $c\in[C]$는 디코더 안에 $C$번만큼의 Conditional layer normalization 가 진행된다는 것을 의미합니다.
Pipeline of AdaSpeech
AdaSpeech는 Pre-training, Fine-tuning, Inference 이렇게 3가지의 Pipeline이 있습니다.

- Pretraining: Source training data (LibriTTS)로 Source TTS 모델인 AdaSpeech를 학습합니다.
- Fine-tuning: 디코더 속 각각의 Conditional layer normalization 동안 $W^\gamma_c$와 $W_c^\beta$, 그리고 Speaker embedding $E^s$만 Fine-tuning 합니다. 그 외에 다른 파라미터들(Utterance-level 인코더, Phoneme-level 인코더, Phoneme-level predictor 등)은 따로 변하지 않고 고정 시켜 놓습니다.
- Inference: $W^\gamma_c$와 $W_c^\beta$ 은 상당히 큰 파라미터를 차지하기 때문에, Conditional layer normalization에서 직접 사용하지 않습니다. 대신에 use the two matrices to calculate each scale and bias vector $\gamma^s_c$ and $β^s_c$ from speaker embedding $E_s$ according to Equation 1 considering $E_s$ is fixed in inference. 이러한 방법으로 저장공간을 많이 절약했습니다.
Experiment setup
Dataset
- Source 모델 학습용 데이터: LibriTTS (2456명 스피커, 586시간)
- Adaptation 학습용 데이터: VCTK(108명, 44시간) & LJSpeech(1명, 24시간) (VCTK랑 LJSpeech는 LibriTTS와 다른 Acoustic condition을 갖고 있음)
- 비교실험을 위해 Adaptation을 LibriTTS로 한 버전도 있습니다.
Data setting
- 먼저 Adaptation을 위해 LibriTTS, VCTK 학습데이터 셋에서 스피커를 랜덤하게 고릅니다.
- 뽑힌 Speaker마다 $K=20$개의 문장을 랜덤하게 고릅니다. 이렇게 뽑힌 $K$개의 문장은 Adaptation(파인튜닝) 과정에 사용됩니다.
- Source 모델을 학습할 때는, LibriTTS에서 (선택된 스피커를 제외한) 모든 스피커를 학습 데이터 셋으로 사용합니다.
- 3가지 데이터 셋 내 기존의 테스트 셋에서 앞서 선택된 스피커들에 대한 데이터만 테스트에 사용합니다.
Preprocessing
- Sampling rate: 16,000Hz
- Hop size: 12.5ms
- Window size: 50ms
- Grapheme-to-Phoneme conversion 사용
Model configuration
- FFT block: Phoneme 인코더에 4개, Mel-spectrogram 디코더에 4개
- Hidden dimension: 256 (Phoneme 임베딩, Speaker 임베딩, Self-attention의 hidden, Feed-forward network의 인풋과 아웃풋의 hidden)
- Attention head: 2
- Feed-forward’s filter size = 1024, kernel size = 9
- Final output Linear layer는 256차원의 hidden을 80차원의 Mel-spectrogram으로 변환
- Phoneme-level acoustic encoder와 predictor는 동일구조
- 2 Convolution layers with filter sizes of 256 and kernel sizes of 3
- Linear layer는 Hidden의 차원을 4로 압축하는 역할
- Vocoder: MelGAN
Training, adaptation and inference
- Training
- 먼저 Source model training 동안 Phoneme-level Acoustic Predictor를 제외한 AdaSpeech 모델의 모든 Parameter를 60,000 스텝동안 학습합니다.
- 그 후에 AdaSpeech와 Phoneme-Predictor를 같이 40,000 스텝동안 학습합니다.
- 이때, Phoneme-level Acoustic encoder가 뱉는 Hidden Output을 Label로 사용해서, MSE loss로 Phoeneme-Predictor를 학습하게 됨. (이 과정에서 Phoneme-level Acoustic encoder에게는 Gradien가 흐르지 않게 합니다.)
- Adpatation
- Adaptation 하는 동안, AdaSpeech를 각 스피커 별로 $K$개의 문장에 대해 2,000 스텝동안 파인튜닝합니다.
- 이 때, Speaker embedding과 Conditional layer normalization의 파라미터들만 최적화 됩니다.
- Inference
- Inference 하는 동안, 해당 스피커(Adaptation 하고자 하는 스피커)의 다른 Reference 스피치에서 Uttrance-level Acoustic condition 을 뽑아내고, Phoneme-Predictor가 Phoneme-level Acoustic condition을 예측하게 됩니다.
Experiment results
Adapation quality
Naturalness와 Similarity를 평가하기 위해서 MOS와 SMOS를 사용하였고, VCTK와 LibriTTS에 대해서는 다양한 Adapted speaker의 최종 스코어를 평균해서 적었습니다.
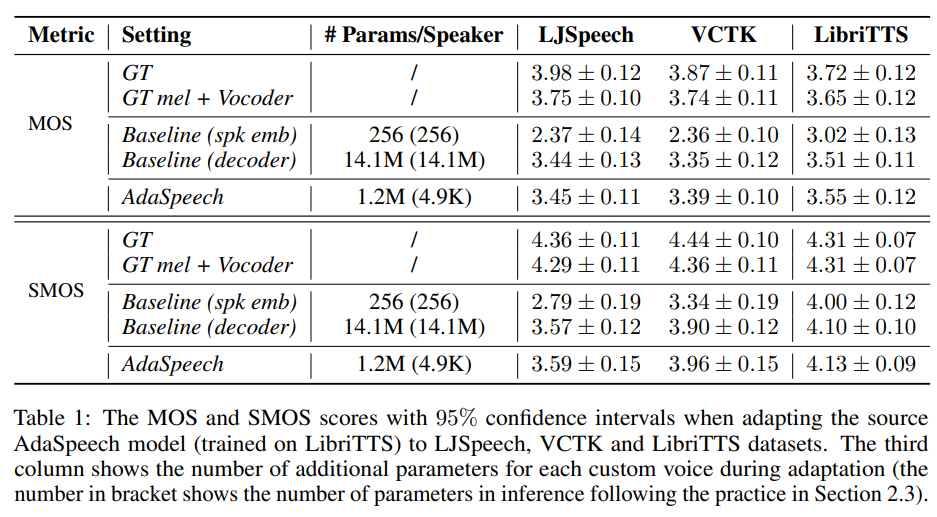
- Cross-domain dataset보다는 In-domain dataset이 좋은 평가를 받았습니다. Cross-domain dataset 자체가 Different Acoustic condition을 모델링해야 하는 일인데, 확실히 Custom Voice 시나리오에서 다른 Acoustic condition을 모델링하는게 어려운 과제라는 것을 확인할 수 있습니다.
- Baseline (spk emb)와 비교했을때 MOS나 SMOS 면에서 훨씬 좋습니다. 물론 Speaker embedding만 파인튜닝하면, 파인튜닝한 파라미터의 숫자가 적긴하지만 성능이 안 좋은건 확실합니다.
- Baseline (decoder)와 비교했을때, MOS나 SMOS 면에서 약간 더 좋습니다. 하지만 파라미터의 숫자가 더 적게 필요하기 때문에 Efficient한 Adaptation을 수행한 것을 증명했습니다.
Ablation study
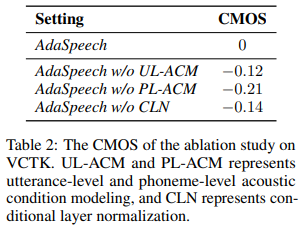
Acoustic condition modeling 분석
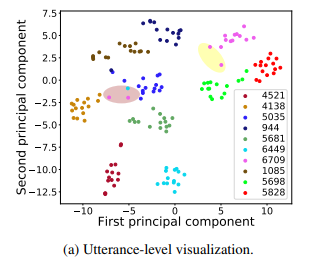
- T-SNE 기법으로 Utterance-level encoder가 만들어낸 벡터를 찍어보았습니다.
- 전체적으로 같은 스피커가 다른 Utterance를 말해도, 스피커 별로 군집화가 잘 되어있습니다.
- 예외적으로 갈색 타원에 속하는 핑크색 점 2개와 청록색 점 1개는 다른 군집에서 멀리 떨어져 있는데, 실제로 찾아 들어보니 Utterance가 짧거나 되게 감정적인 Voice가 들어가서 스피커별 군집이 잘 안 되었다고 합니다.
Conditional layer normalization 분석

Adaptation data 개수 분석