FastSpeech 2
in Seminar on Text-to-Speech


- Waveform Decoder를 학습할 때,
- Waveform 길이 자체가 엄청 길기 때문에 short audio clip으로 잘라서 학습을 함
여기서 Mel-spectrogram decoder도 같이 학습을 하는데,
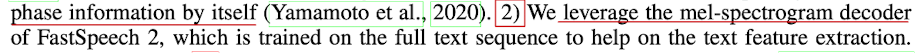
- mel-spectrogram decoder를 활용한다는 말이 앞단에서 phoneme sequence 정보를 잘 학습하기 위해 Mel-spectrogram decoder의 loss도 같이 활용해서 학습을 한다는 말이였음
Waveform Decoder에서는 audio를 일부만 잘라서 학습을 하기 때문에 그 부분에 대한 gradient만 흐르니까 전체 sequence에 대해 학습을 잘하기 위해서 mel-spectrogram decoder에서 전체 mel에 대한 loss를 같이 활용하는 것임
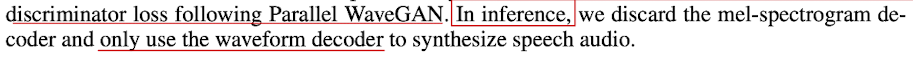
- 그리고 inference때는 waveform decoder만 활용해서 text ⇒ waveform과정을 보여줌
- Pitch predictor에서 실제로 쓸 때,
- speaker별로 normalization을 해주기도 하고 전체 데이터 셋에 대해서도 normalization을 해주기도 함
- Pitch spectrogram을 뽑는데 STFT도 있는데 왜 CWT 썼을까?
- CWT가 좋은 경우가 있고 STFT가 좋은 경우가 있음
- STFT가 trade off를 극복한 경우도 있어서 CWT를 사용한 것이 처음에 의문이였다고 하심
- 이후 논문에는 pitch spectrogram이 아닌 pitch 값을 예측하는 경우도 많음
- normalization을 해서 log scale로 바꾸어 주면 더 쉽게 예측이 잘되는 경우도 많음
- 여기서는 MSE loss를 썼는데, 선배님이 실험을 했을때는 RMSE, MSE, L1을 비교했을때 RMSE가 제일 좋았고, MSE보다는 L1이 조금 더 좋았던거 같다. 데이터마다 다르긴 한데 일반적으로 L1을 써도 괜찮은 거 같음
- pitch를 같이 써주면 대체로 좋음. TTS든 VC든
- pitch 뽑는게 꽤 오래 걸림
FastSpeech 2s 학습 시간이 왜 이렇게 오래 걸릴까?


- FastSpeech 2s를 제외한 3개 모델은 vocoder training학습 시간까지 고려하지 않은 Training time을 적어놓음
- 어쨌든 Waveform을 End-to-End로 학습하는 것은 꽤 오래걸린다를 알고있으면 됨
- End-to-End의 장점은 무엇일까?
- two stage 모델은 오류가 누적된다라는 단점이 있음, 각각 장단점이 있음
- End-to-End는 학습시간이 오래 걸린다는 단점이 있음
- two stage 같은 경우에는 vocoder만 있으면 mel feature가져와서 바로 바로 확인할 수 있음
- two stage 같은 경우 아무리 mel을 잘 만들어도 vocoder가 좋아도 한계가 있음
- 잘 만든 mel이라도 vocoder에서는 본 적없는 mel
- End-to-End는 그에 비해 음질이 좋은데 학습이 오래 걸리는 단점